🍳머리말
pod lifecycle에 대한 k8s docs 복붙글입니다.
📕 Pod
Pod는 k8s가 인식할 수 있는 최소의 단위입니다. 하나의 node에 1개 이상의 pod가 있으며, pod에는 1개 이상의 container로 구성됩니다.
📔 Lifecycle
Pod 생성 시 Pending 단계에서 시작해서, 기본 컨테이너 중 적어도 하나 이상이 OK로 시작하면 Running 단계를 통과하고, 그런 다음 파드의 컨테이너가 실패로 종료되었는지 여부에 따라 Succeeded 또는 Failed 단계로 이동합니다.
파드가 실행되는 동안, kubelet은 일종의 오류를 처리하기 위해 컨테이너를 다시 시작할 수 있습니다. 교착 상태의 container를 다시 실행한다면 가용성을 높여줄 수 있기 때문입니다. 파드 내에서, 쿠버네티스는 다양한 컨테이너 상태를 추적하고 파드를 다시 정상 상태로 만들기 위해 취할 조치를 결정합니다.
쿠버네티스 API에서 파드는 명세와 실제 상태를 모두 가집니다. 파드 오브젝트의 상태는 일련의 파드의 조건들로 구성된다. 사용자의 애플리케이션에 유용한 경우, 파드의 조건 데이터에 사용자 정의 준비성 정보를 삽입할 수도 있습니다.
파드는 파드의 수명 중 한 번만 스케줄됩니다. 파드가 노드에 스케줄(할당)되면, 파드는 중지되거나 종료될 때까지 해당 노드에서 실행됩니다.
📔 수명
개별 application conainer과 마찬가지로 pod는 임시 entity로 간주됩니다. pod가 생성되고 고유 ID(UID)가 할당되고, 종료 또는 삭제될 때까지 남아있는 node에 schedule됩니다. 만약 node가 종료되면 해당 node에 schedule된 pods는 timeout 기간 후에 삭제되도록 schedule됩니다.
Pod는 자체적으로 자가 치유되지 않습니다. pod가 node에 schedule된 후에 해당 ndoe가 실패하면 pod는 삭제됩니다. 마찬가지로 pod는 resource 부족 또는 node 유지 관리 작업으로 인한 축출로도 삭제될 수 있습니다. k8s는 controller라 부르는 high-level-abstraction을 사용해 상대적으로 일회용인 pod instance를 관리하는 작업을 처리합니다.
UID로 정의된 특정 pod는 다른 node로 절대 "다시 schedule"되지 않는다. 대신, 해당 pod는 사용자가 원한다면 이름은 같지만 UID가 다른 거의 동일한 새 pod로 대체될 수 있습니다.
Volume과 같은 어떤 것이 pod와 동일한 수명을 갖는다는 것은, 특정 pod가 존재하는 한 그것이 존재함을 의미합니다. 어떤 이유든 해당 pod가 삭제되고, 동일한 대체 pod가 생성되더라도, 관련된 volume등 도 폐기되고 새로 생성됩니다.
📔 Phase
Pod의 status filed는 phase field를 포함하는 pod status object로 정의됩니다.
Pod의 phase는 pod가 life cycle 중 어느 단계에 해당하는지 표현하는 간단한 고수준의 요약입니다. Phase는 continer나 pod의 관측 정보에 대한 포괄적인 roll up이나, 포괄적인 상태 머신을 표현하도록 의도한 것은 아닙니다.
Pod phase 값에서 숫자와 의미는 엄격하게 지켜집니다. pod와 pod에 주어진 phase값에 대해 어떤 사항도 가정되어서는 안됩니다.
Phase에 가능한 값은 다음과 같습니다.
| 값 | 의미 |
| Pending | pod가 k8s cluster에서 승인되었으나 하나 이상의 container가 설정되지 않았고 실행할 준비가 되지 않았습니다. 여기에는 pod가 schedule되기 이전까지의 시간 뿐만 아니라 network를 통한 container image download 시간도 포함됩니다. yaml로 pod spec을 작성할 때 apply하게 되면 모든 container가 생성될때까지 해당 상태가 유지됩니다. |
| Running | pod가 node에 binding되었고 모든 container가 생성되었습니다. 적어도 하나의 container가 아직 실행중이거나 시작 또는 재시작 중에 있습니다. |
| Succeeded | pod에 있는 모든 container들이 성공적으로 종료되었고 재시작되지 않을 것입니다. |
| Failed | pod에 있는 모든 container가 종료된 상태에서 적어도 하나 이상의 container가 실패로 종료된 상태입니다. 즉, 해당 container는 non-zero상태로 빠져나왔거나(exited) system에 의해 종료(terminated)되었습니다. |
| Unknown | 어떤 이유에 의해서 pod의 상태를 얻을 수 없습니다. 이 단계는 일반적으로 pod가 실행되어야 하는 node와의 통신 오류로 인해 발생한다. |
참고: 파드가 삭제될 때, 일부 kubectl 커맨드에서 Terminating 이 표시되는데. 이는 파드의 단계에 해당하지 않습니다. 파드에는 그레이스풀하게(gracefully) 종료되도록 기간이 부여되며, 그 기본값은 30초입니다. 강제로 pod를 종료하려면 --force 플래그를 설정하면 됩니다.
📔 Pod의 조건
pod는 하나의 PodStatus를 가지며, 그것은 pod가 통과했더나 통과하지 못한 조건에 대한 PodConditions 배열을 가집니다.
- PodScheduled: 파드가 노드에 스케줄됨.
- ContainersReady: 파드의 모든 컨테이너가 준비됨.
- Initialized: 모든 초기화 컨테이너가 성공적으로 시작됨.
- Ready: 파드는 요청을 처리할 수 있으며 일치하는 모든 서비스의 로드 밸런싱 풀에 추가되어야 함.
PodCondition 배열의 각 요소는 다음 여섯 가지 필드를 가질 수 있습니다.
| 필드 | 이름설명 |
| type | 이 파드 조건의 이름이다. |
| status | 가능한 값이 "True", "False", 또는 "Unknown"으로, 해당 조건이 적용 가능한지 여부를 나타낸다. |
| lastProbeTime | 파드 조건이 마지막으로 프로브된 시간의 타임스탬프이다. |
| lastTransitionTime | 파드가 한 상태에서 다른 상태로 전환된 마지막 시간에 대한 타임스탬프이다. |
| reason | 조건의 마지막 전환에 대한 이유를 나타내는 기계가 판독 가능한 UpperCamelCase 텍스트이다. |
| message | 마지막 상태 전환에 대한 세부 정보를 나타내는 사람이 읽을 수 있는 메시지이다. |
📔 Pod의 readiness
application은 추가 feedback 또는 신호를 PodStatus: Pod readiness와 같이 주입할 수 있습니다. 이를 사용하기 위해, kubelet이 pod의 준비성을 평가하기 위한 추가적인 조건들을 pod의 spec내 readinessGate field를 통해 지정할 수 있습니다. ReadinessGate는 pod에 대한 status.condition field의 현재 상태에 따라 결정됩니다. 만약 k8s가 status.conditions field에서 해당하는 조건을 찾지 못한다면 그 조건의 상태는 기본 값인 False가 됩니다.
ex)
kind: Pod
...
spec:
readinessGates:
- conditionType: "www.example.com/feature-1"
status:
conditions:
- type: Ready # 내장된 PodCondition이다
status: "False"
lastProbeTime: null
lastTransitionTime: 2018-01-01T00:00:00Z
- type: "www.example.com/feature-1" # 추가적인 PodCondition
status: "False"
lastProbeTime: null
lastTransitionTime: 2018-01-01T00:00:00Z
containerStatuses:
- containerID: docker://abcd...
ready: true
...추가하는 파드 상태에는 쿠버네티스 레이블 키 포맷을 충족하는 이름이 있어야 합니다.
📔 Pod의 종료
pod는 cluster의 node에서 실행되는 process를 나타내므로, 해당 process가 더 이상 필요하지 않을 때 정상적으로 종료되도록 하는 것이 중요합니다. kill sig로 정리하게 되면 정리할 기회가 없어지기 때문입니다.
Design 목표는 삭제를 요청하고 process가 종료되는 시기를 알 수 있을 뿐만 아니라, 삭제가 결국 완료되도록 하는 것입니다. 사용자가 pod의 삭제를 요청하면, cluster는 pod가 강제로 종료되기 전에 의도한 유예 기간을 기록하고 추적합니다. 강제 종료 추적이 적용되면 kubelet은 정상 종료를 시도합니다.
일반적으로, container runtime은 각 container의 기본 process에 TERM 신호를 전송합니다. 많은 container runtime은 container image에 정의된 STOPSIGNAL값을 존중하며 TERM대신 이 값을 보냅니다. 일단 유예 기간이 만료되면, KILL SIGNAL이 나머지 process로 전송되고 pod는 API server로부터 삭제됩니다. process가 종료될 때까지 기다리는 동안 kubelet 또는 container runtime의 관리 service가 다시 시작되면 cluster는 전체 원래 유예 기간을 포함해 처음부터 다시 시도합니다.
다음은 종료 flow의 한 예시입니다
1. kubectl 도구를 사용해 기본 유예 기간(30초)로 특정 pod를 수동으로 삭제합니다.
2. API server의 pod는 유예 기간과 함께 pod가 "dead"로 간주되는 시간으로 update됩니다. kubectl describe를 사용해 삭제하려는 pod를 확인하면 해당 pod가 Terminating으로 표시됩니다. pod가 실행 중인 node에서 kubelet이 pod가 종료된 것으로 표시되었을 확인하는 즉시 정상적인 종료 기간이 설정됩니다. kubelet은 local pod의 종료 process를 시작합니다.
- 파드의 컨테이너 중 하나가 preStop 훅을 정의한 경우, kubelet은 컨테이너 내부에서 해당 훅을 실행. 유예 기간이 만료된 후 preStop 훅이 계속 실행되면, kubelet은 2초의 작은 일회성 유예 기간 연장을 요청.
참고: preStop 훅을 완료하는 데 기본 유예 기간이 허용하는 것보다 오랜 시간이 필요한 경우, 이에 맞게 terminationGracePeriodSeconds 를 수정해야 함.
- kubelet은 컨테이너 런타임을 트리거하여 각 컨테이너 내부의 프로세스 1에 TERM 시그널을 보냄.
참고: 파드의 컨테이너는 서로 다른 시간에 임의의 순서로 TERM 시그널을 수신한다. 종료 순서가 중요한 경우, preStop 훅을 사용하여 동기화하는 것이 좋음.
3. kubelet이 정상 종료를 시작하는 동시에, 컨트롤 플레인은 구성된 셀렉터가 있는 서비스를 나타내는 엔드포인트(Endpoint)(그리고, 활성화된 경우, 엔드포인트슬라이스(EndpointSlice)) 오브젝트에서 종료된 파드를 제거. 레플리카셋(ReplicaSet)과 기타 워크로드 리소스는 더 이상 종료된 파드를 유효한 서비스 내 복제본으로 취급하지 않음. 로드 밸런서(서비스 프록시와 같은)가 종료 유예 기간이 시작되는 즉시 엔드포인트 목록에서 파드를 제거하므로 느리게 종료되는 파드는 트래픽을 계속 제공할 수 없음.
4. 유예 기간이 만료되면, kubelet은 강제 종료를 트리거함. 컨테이너 런타임은 SIGKILL 을 파드의 모든 컨테이너에서 여전히 실행 중인 모든 프로세스로 전송. kubelet은 해당 컨테이너 런타임이 하나를 사용하는 경우 숨겨진 pause 컨테이너도 정리함.
5. kubelet은 유예 기간을 0(즉시 삭제)으로 설정하여, API 서버에서 파드 오브젝트의 강제 삭제를 트리거함.
6. API 서버가 파드의 API 오브젝트를 삭제하면, 더 이상 클라이언트에서 볼 수 없음.
📔 Pod 강제 종료
*강제 삭제는 일부 workload와 해당 pod에 대해 잠재적으로 중단될 수 있습니다.기본적으로 모든 삭제는 30초 이내 정상적으로 수행됩니다. kubectl delete명령은 기본값을 재정의하고 사용자의 고유한 값을 지정할 수 있는 --greace-perid=<seconds> option을 지원합니다. 유예 기간을 0으로 강제 설정하면 API server에서는 pod가 삭제됩니다. pod가 node에서 계속 실행 중인 경우, 강제 삭제는 kubelet을 trigger하여 즉시 정리를 시작합니다. 강제 삭제는 --grace-period=0 와 함께 추가 플래그 --force 를 지정해야 합니다.강제 삭제가 수행되면, API server는 실행 중인 node에서 pod가 종료되었다는 kubelet의 확인을 기다리지 않습니다. API에서 즉시 pod를 제거하므로 동일한 이름으로 새로운 pod를 생성할 수 있습니다. node에서 즉시 종료되도록 설정된 pod는 강제 종료되기 전에 작은 유예 기간이 계속 제공됩니다.
📔 실패 pod의 garbage collection
실패한 pod의 경우, API object는 사람이나 controller process가 명시적으로 pod를 제거할 때까지 cluster의 API에 남아있습니다. control plane은 pod수가 구성된 임계값을 초과할 때 terminated, succeeded, failed된 pod를 정리합니다. 이렇게 하면 시간이 지남에 따라 pod가 생성되고 종료될 때 resource 유출이 방지됩니다.
📕 Container
📔 상태
전체 pod의 단계뿐 아니라 k8s는 pod 내부의 각 container 상태를 추적합니다. container lifecycle hook을 사용해 container lifecycle의 특정 지점에서 실행할 event를 trigger할 수 있습니다.
일단 scheduler가 node에 pod를 할당하면 kubelet은 container runtime(cri-o, docker 등)을 사용해 해당 pod에 대한 container 생성을 시작합니다. 표시될 수 있는 3가지 container 상태는 다음과 같습니다.
| 상태명 | 의미 |
| Waiting | 시작을 완료하는데 필요한 작업(container image registry에서 container image pull, secret data를 적용하는 등)을 계속 실행하는 중입니다. |
| Running | 문제없이 container가 실행되고 있음을 나타냅니다. postStart hook이 구성되어 있었다면 이미 실행되고 완료되었을 것입니다. kubectl을 사용해 container가 running인 pod를 query하면 container가 running상태에 진입한 시기 정보를 볼 수 있습니다. |
| Terminated | container를 실행시작한 다음 완료될 때까지 실행되었거나 어떤 이유로 실패한 상태입니다. kubectl을 사용해 container가 terminated인 pod를 query하면 이유와 종료 code, 해당 container의 실행 기간에 대한 시작과 종료 시간이 표시됩니다. Container에 구성된 preStop hook이 있는 경우, container가 terminated상태에 들어가기 전에 실행됩니다. |
📔 재시작 정책
pod의 spec에는 restartPolicy가 있습니다. 가용값은 Always, OnFailure, Never입니다. default는 Always입니다. restartPolicy는 pod의 모든 container에 적용됩니다. restartPolicy는 동일한 node에서 kubelet에 의한 container 재시작만을 의미합니다. pod의 container가 종료된 후 kubelet은 5분으로 제한되는 지수 backoff delay(10, 20, 40초, ...)로 container를 재시작합니다. container가 10분 동안 아무런 문제없이 실행되면, kubelet은 해당 container의 재시작 backoff timer를 재설정합니다.
📔 Probe
Probe는 conatiner에서 kubelet에 의해 주기적으로 수행되는 진단입니다. 진단을 수행하기 위해 kubelet은 container에 의해 구현된 handler를 호출합니다. handler에는 다음과 같이 3가지 type이 있습니다.
- ExecAction : 컨테이너 내에서 지정된 명령어를 실행한다. 명령어가 상태 코드 0으로 종료되면 진단이 성공한 것으로 간주.
- TCPSocketAction : 지정된 포트에서 컨테이너의 IP주소에 대해 TCP 검사를 수행. 포트가 활성화되어 있다면 진단이 성공한 것으로 간주.
- HttpGetAction : 지정한 포트 및 경로에서 컨테이너의 IP주소에 대한 HTTP GET 요청을 수행. 응답의 상태 코드가 200 이상 400 미만이면 진단이 성공한 것으로 간주.
각 probe는 다음 세 가지 결과 중 하나를 가집니다.
| 결과 | 의미 |
| Success | container가 진단을 통과 |
| Failure | container가 진단 실패 |
| Unknown | 진단 자체를 실패했음. 아무런 action도 수행되면 안됨 |
kubelet은 실행 중인 컨테이너들에 대해서 선택적으로 세 가지 종류의 프로브를 수행하고 그에 반응할 수 있습니다.
- livenessProbe: 컨테이너가 동작 중인지 여부를 나타냅니다. 만약 활성 프로브(liveness probe)에 실패한다면, kubelet은 컨테이너를 죽이고, 해당 컨테이너는 재시작 정책의 대상이 됩니다. 만약 컨테이너가 활성 프로브를 제공하지 않는 경우, 기본 상태는 Success입니다.
- readinessProbe: 컨테이너가 요청을 처리할 준비가 되었는지 여부를 나타냅니다. 만약 준비성 프로브(readiness probe)가 실패한다면, 엔드포인트 컨트롤러는 파드에 연관된 모든 서비스들의 엔드포인트에서 파드의 IP주소를 제거합니다. 준비성 프로브의 초기 지연 이전의 기본 상태는 Failure입니다. 만약 컨테이너가 준비성 프로브를 지원하지 않는다면, 기본 상태는 Success입니다.
- startupProbe: 컨테이너 내의 애플리케이션이 시작되었는지를 나타냅니다. 스타트업 프로브(startup probe)가 주어진 경우, 성공할 때까지 다른 나머지 프로브는 활성화되지 않습니다. 만약 스타트업 프로브가 실패하면, kubelet이 컨테이너를 죽이고, 컨테이너는 재시작 정책에 따라 처리됩니다. 컨테이너에 스타트업 프로브가 없는 경우, 기본 상태는 Success입니다.
📑 언제 livenessProbe 사용?
만약 컨테이너 속 프로세스가 어떠한 이슈에 직면하거나 건강하지 못한 상태(unhealthy)가 되는 등 프로세스 자체의 문제로 중단될 수 있더라도, 활성 프로브가 반드시 필요한 것은 아니다. 그 경우에는 kubelet이 파드의 restartPolicy에 따라서 올바른 대처를 자동적으로 수행할 것이다.
프로브가 실패한 후 컨테이너가 종료되거나 재시작되길 원한다면, 활성 프로브를 지정하고, restartPolicy를 항상(Always) 또는 실패 시(OnFailure)로 지정한다.
📑 언제 readinessProbe 사용?
Probe가 성공한 경우만 pod에 traffic 전송을 시작하려고 할 때 지정됩니다. 이 경우에 livenessProbe와 유사해 보이나 spec에 readinessProbe가 존재한다는 것은 pod가 traffic을 받지 않는 상태에서 시작되고 probe가 성공하기 시작한 이후에만 traffic을 받는다는 뜻입니다.
만약 container가 유지 관리를 위해 자체 중단되게 할 때도 사용됩니다. livenessProbe와 다르게 준비성에 특정된 end point를 확인합니다.
만약 애플리케이션이 백엔드 서비스에 엄격한 의존성이 있다면, 활성 프로브와 준비성 프로브 모두 활용할 수도 있습니다. 활성 프로브는 애플리케이션 스스로가 건강한 상태면 통과하지만, 준비성 프로브는 추가적으로 요구되는 각 백-엔드 서비스가 가용한지 확인합니다. 이를 이용하여, 오류 메시지만 응답하는 파드로 트래픽이 가는 것을 막을 수 있습니다.
만약 컨테이너가 시동 시 대량 데이터의 로딩, 구성 파일, 또는 마이그레이션에 대한 작업을 수행해야 한다면, statupProbe를 사용하면 됩니다. 그러나, 만약 failed 애플리케이션과 시동 중에 아직 데이터를 처리하고 있는 애플리케이션을 구분하여 탐지하고 싶다면, 준비성 프로브를 사용하는 것이 더 적합할 것입니다.
중요성
readinessProbe는 frontend pod의 통신이 불량인 경우 이와 통신하지 않고 client가 정상 상태의 pod하고만 통신하게 함으로써 system에 장애가 있다는 것을 모르게 합니다. 또한 그 신호는 k8s에만 알려줌으로써 개발자가 error를 잡을 수 있게 합니다.
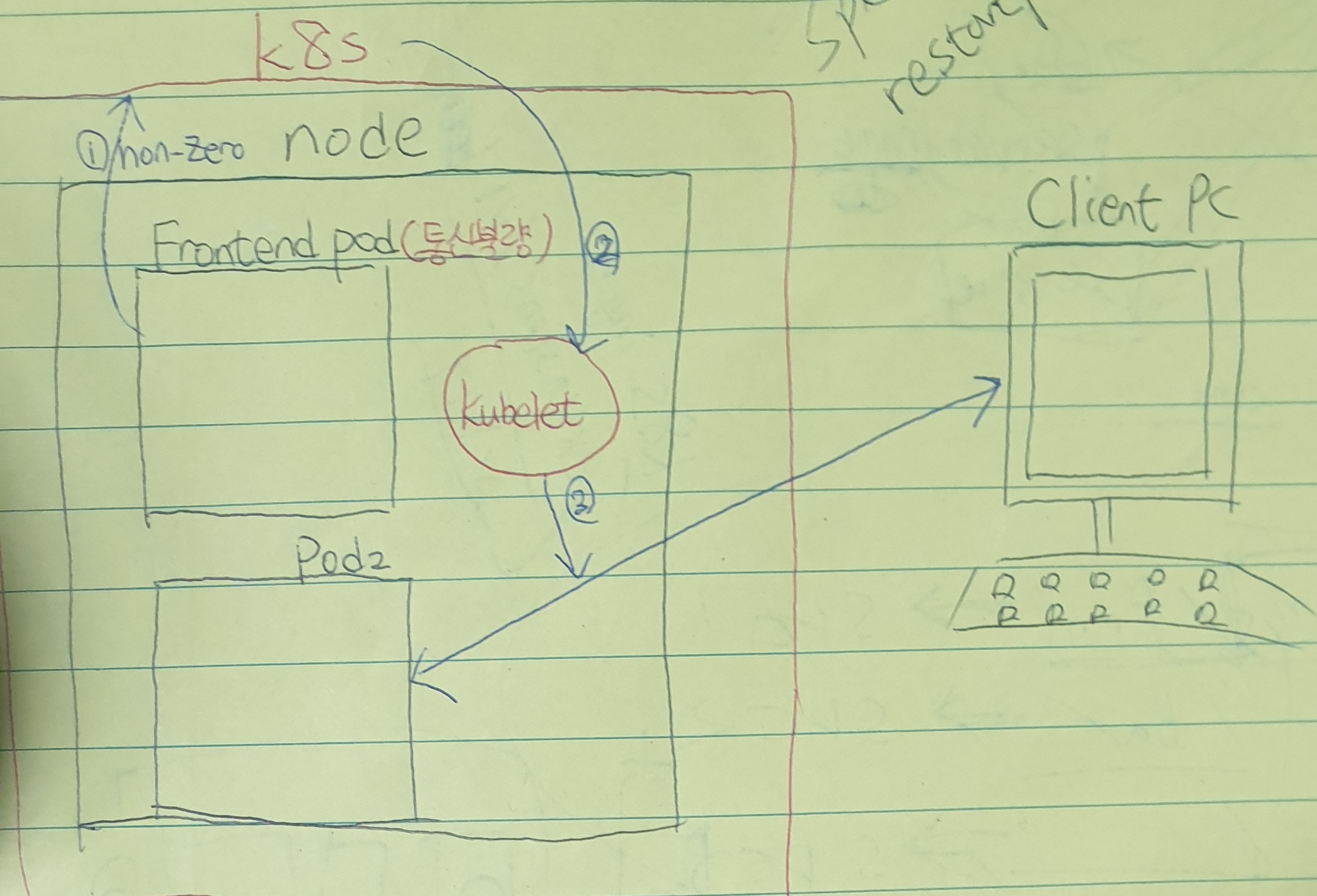
1. frontend pod가 요청처리 준비가 안되어 있음을 non-zero신호로 표현되며 이를 k8s로 송신합니다.
2. k8s는 kubelet에게 하여금 pod의 불량을 알려줍니다.
3. kubelet은 요청 처리 준비가 된 정상 pod2와 client를 통신하도록 합니다.
📑 언제 startupProbe 사용?
스타트업 프로브는 서비스를 시작하는 데 오랜 시간이 걸리는 컨테이너가 있는 파드에 유용합니다. 긴 활성 간격을 설정하는 대신, 컨테이너가 시작될 때 프로브를 위한 별도의 구성을 설정하여, 활성 간격보다 긴 시간을 허용할 수 있습니다.
컨테이너가 보통 initialDelaySeconds + failureThreshold × periodSeconds 이후에 기동된다면, 스타트업 프로브가 활성화 프로브와 같은 엔드포인트를 확인하도록 지정해야 합니다. periodSeconds의 기본값은 10s 입니다. 이 때 컨테이너가 활성화 프로브의 기본값 변경 없이 기동되도록 하려면, failureThreshold 를 충분히 높게 설정해주어야 합니다. 그래야 데드락(deadlocks)을 방지하는데 도움이 됩니다.
📕참조
https://kubernetes.io/ko/docs/concepts/workloads/pods/pod-lifecycle/
파드 라이프사이클
이 페이지에서는 파드의 라이프사이클을 설명한다. 파드는 정의된 라이프사이클을 따른다. Pending 단계에서 시작해서, 기본 컨테이너 중 적어도 하나 이상이 OK로 시작하면 Running 단계를 통과하
kubernetes.io
'Cloud' 카테고리의 다른 글
| (Kubernetes) - operator pattern (0) | 2021.11.17 |
|---|---|
| (Kubernetes) - init container (0) | 2021.11.15 |
| (Kubernetes) - k8s namespace 생성하기 (0) | 2021.11.09 |
| (Kubernetes) - storage (0) | 2021.10.26 |
| (Kubernetes) - workload (0) | 2021.10.20 |